

Die Zukunft des Deep Learning kann in diese 3 Lernparadigmen unterteilt werden

Die Zukunft des Deep Learning kann in diese 3 Lernparadigmen unterteilt werden
Hybrides, zusammengesetztes und reduziertes Lernen
Ursprüngliche Webseite:
Deep Learning ist ein weites Feld, in dessen Mittelpunkt ein Algorithmus steht, dessen Form von Millionen oder sogar Milliarden von Variablen bestimmt wird und ständig verändert wird – das neuronale Netz. Es scheint, dass jeden zweiten Tag überwältigende Mengen neuer Methoden und Techniken vorgeschlagen werden.
Generell lässt sich Deep Learning in der Neuzeit jedoch in drei grundlegende Lernparadigmen unterteilen. In jedem liegt ein Ansatz und eine Überzeugung zum Lernen, die erhebliches Potenzial und Interesse bieten, um die derzeitige Leistungsfähigkeit und den Umfang des Deep Learning zu erhöhen.
Hybrides Lernen — Wie können moderne Deep-Learning-Methoden die Grenzen zwischen überwachtem und unüberwachtem Lernen überwinden, um eine große Menge ungenutzter, nicht gekennzeichneter Daten zu verarbeiten?
Zusammengesetztes Lernen — Wie können verschiedene Modelle oder Komponenten in kreativen Methoden verbunden werden, um ein zusammengesetztes Modell zu erzeugen, das größer ist als die Summe seiner Teile?
Reduziertes Lernen — Wie können sowohl die Größe als auch der Informationsfluss von Modellen sowohl aus Leistungs- als auch aus Bereitstellungsgründen reduziert werden, während gleichzeitig die gleiche oder eine höhere Vorhersagekraft beibehalten wird?
Die Zukunft des Deep Learning liegt in diesen drei Lernparadigmen, die alle stark miteinander verbunden sind.
Hybrides Lernen
Dieses Paradigma versucht, die Grenzen zwischen überwachtem und unüberwachtem Lernen zu überschreiten. Es wird häufig im geschäftlichen Kontext verwendet, da gekennzeichnete Daten fehlen und teuer sind. Im Wesentlichen ist hybrides Lernen eine Antwort auf die Frage,
Wie kann ich überwachte Methoden verwenden, um/in Verbindung mit unüberwachten Problemen zu lösen?
Zum einen gewinnt semi-überwachtes Lernen in der Gemeinschaft des maschinellen Lernens an Boden, da es in der Lage ist, bei überwachten Problemen mit wenigen gekennzeichneten Daten außergewöhnlich gute Leistungen zu erbringen. Beispielsweise erreichte ein gut konzipiertes semi-überwachtes GAN (Generative Adversarial Network) eine Genauigkeit von über 90 % beim MNIST-Datensatz, nachdem es gesehen wurde nur 25 Trainingsbeispiele.
Semi-überwachtes Lernen ist für Datensätze konzipiert, in denen viele unüberwachte Daten, aber kleine Mengen überwachter Daten vorhanden sind. Während traditionell ein überwachtes Lernmodell auf einem Teil der Daten und ein unüberwachtes Modell auf dem anderen trainiert wird, kann ein halbüberwachtes Modell gekennzeichnete Daten mit Erkenntnissen kombinieren, die aus nicht gekennzeichneten Daten extrahiert wurden.
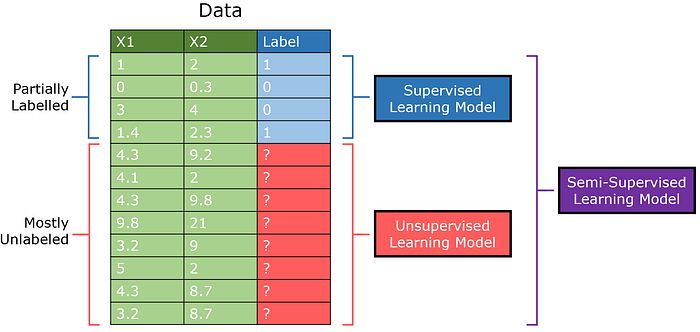
Das semi-überwachte GAN (abgekürzt als SGAN) ist eine Adaption des Standards Generatives Adversarial Network-Modell. Der Diskriminator gibt sowohl 0/1 aus, um anzuzeigen, ob ein Bild erzeugt wird oder nicht, aber er gibt auch die Klasse des Elements aus (Multiausgangslernen).
Dies basiert auf der Idee, dass der Diskriminator durch das Erlernen der Unterscheidung zwischen realen und generierten Bildern in der Lage ist, deren Strukturen ohne konkrete Labels zu lernen. Mit zusätzlicher Verstärkung durch eine kleine Menge an gekennzeichneten Daten können semi-überwachte Modelle Spitzenleistungen mit minimalen Mengen überwachter Daten erzielen.
Sie können mehr über SGANs und teilüberwachtes Lernen lesen Hier.
GANs sind auch in einem anderen Bereich des hybriden Lernens beteiligt — selbstüberwacht Lernen, bei dem unüberwachte Probleme explizit als überwachte Probleme bezeichnet werden. GANs erzeugen durch die Einführung eines Generators künstlich überwachte Daten; Etiketten werden erstellt, um echte/erzeugte Bilder zu identifizieren. Aus einer unbeaufsichtigten Prämisse wurde eine überwachte Aufgabe erstellt.
Betrachten Sie alternativ die Verwendung von Encoder-Decoder-Modelle zur Kompression. In ihrer einfachsten Form sind sie neuronale Netze mit einer kleinen Anzahl von Knoten in der Mitte, um eine Art komprimierter Flaschenhalsform darzustellen. Die beiden Abschnitte auf beiden Seiten sind der Encoder und der Decoder.
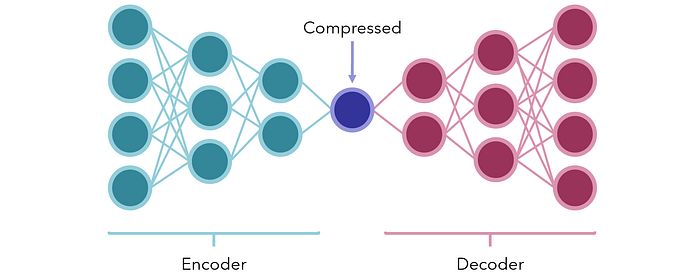
Das Netzwerk ist darauf trainiert, die gleich Ausgabe als Vektoreingabe (eine künstlich erstellte überwachte Aufgabe aus nicht überwachten Daten). Da sich in der Mitte ein bewusster Engpass befindet, kann das Netzwerk die Informationen nicht passiv weitergeben; stattdessen muss es die besten Wege finden, um den Inhalt der Eingabe in einer kleinen Einheit zu bewahren, so dass er vom Decoder vernünftigerweise wieder dekodiert werden kann.
Nach dem Trainieren werden der Codierer und der Decodierer auseinandergenommen und können an den Empfangsenden komprimierter oder codierter Daten verwendet werden, um Informationen in extrem kleiner Form mit wenig bis keinem Datenverlust zu übertragen. Sie können auch verwendet werden, um die Dimensionalität von Daten zu reduzieren.
Betrachten Sie als weiteres Beispiel eine große Sammlung von Texten (vielleicht Kommentare von einer digitalen Plattform). Durch einige Clustering oder vielfältiges Lernen Methode können wir Cluster-Labels für Textsammlungen generieren und diese dann als Labels behandeln (vorausgesetzt, das Clustering ist gut gemacht).
Nachdem jeder Cluster interpretiert wurde (zB Cluster A steht für Kommentare, die sich über ein Produkt beschweren, Cluster B steht für positives Feedback usw.) eine tiefe NLP-Architektur wie BERT können dann verwendet werden, um neue Texte in diese Cluster zu klassifizieren, alle mit völlig unmarkierten Daten und minimalem menschlichem Engagement.
Dies ist wiederum eine faszinierende Anwendung, um unbeaufsichtigte Aufgaben in überwachte umzuwandeln. In einer Zeit, in der die überwiegende Mehrheit aller Daten unüberwachte Daten sind, liegt ein enormer Wert und ein enormes Potenzial darin, kreative Brücken zu bauen, um die Grenzen zwischen überwachtem und unüberwachtem Lernen mit hybridem Lernen zu überschreiten.
Zusammengesetztes Lernen
Zusammengesetztes Lernen versucht, das Wissen nicht eines Modells, sondern mehrerer Modelle zu nutzen. Es ist die Überzeugung, dass Deep Learning durch einzigartige Kombinationen oder Injektionen von Informationen – sowohl statisch als auch dynamisch – das Verständnis und die Leistung kontinuierlich vertiefen kann als ein einzelnes Modell.
Transferlernen ist ein offensichtliches Beispiel für zusammengesetztes Lernen und basiert auf der Idee, dass die Gewichte eines Modells von einem Modell übernommen werden können, das für eine ähnliche Aufgabe vortrainiert und dann auf eine bestimmte Aufgabe abgestimmt wird. Vortrainierte Modelle wie Anfang oder VGG-16 sind mit Architekturen und Gewichtungen ausgestattet, die darauf ausgelegt sind, zwischen mehreren verschiedenen Bildklassen zu unterscheiden.
Wenn ich ein neuronales Netzwerk trainieren würde, um Tiere (Katzen, Hunde usw.) zu erkennen, würde ich ein neuronales Faltungsnetzwerk nicht von Grund auf trainieren, da es zu lange dauern würde, um gute Ergebnisse zu erzielen. Stattdessen würde ich ein vortrainiertes Modell wie Inception nehmen, das bereits die Grundlagen der Bilderkennung gespeichert hat, und für einige zusätzliche Epochen des Datensatzes trainieren.
Ebenso Worteinbettungen in neuronalen NLP-Netzen, die Wörter in Abhängigkeit von ihren Beziehungen physisch näher an andere Wörter in einem Einbettungsraum abbilden (zB 'Apfel' und 'Orange' haben kleinere Abstände als 'Apfel' und 'LKW'). Vortrainierte Einbettungen wie GloVe können in neuronale Netze platziert werden, um mit einer bereits effektiven Zuordnung von Wörtern zu numerischen, bedeutungsvollen Einheiten zu beginnen.
Weniger offensichtlich kann Wettbewerb auch das Wissenswachstum stimulieren. Zum einen entlehnen Generative Adversarial Networks vom zusammengesetzten Lernparadigma, indem sie grundsätzlich zwei neuronale Netze gegeneinander ausspielen. Das Ziel des Generators besteht darin, den Diskriminator auszutricksen, und das Ziel des Diskriminators besteht darin, nicht ausgetrickst zu werden.
Der Wettbewerb zwischen den Modellen wird als „kontradiktorisches Lernen“ bezeichnet, nicht zu verwechseln mit einer anderen Art des kontradiktorischen Lernens, das sich auf die Entwerfen bösartiger Eingaben und Ausnutzen schwacher Entscheidungsgrenzen in Modellen.
Kontradiktorisches Lernen kann Modelle stimulieren, in der Regel unterschiedlicher Art, in denen die Leistung eines Modells im Verhältnis zur Leistung anderer dargestellt werden kann. Auf dem Gebiet des kontradiktorischen Lernens gibt es noch viel Forschungsbedarf, wobei das generative kontradiktorische Netzwerk die einzige prominente Kreation des Teilbereichs ist.
Das kompetitive Lernen hingegen ähnelt dem kontradiktorischen Lernen, wird jedoch auf der Skala von Knoten zu Knoten durchgeführt: Knoten konkurrieren um das Recht, auf eine Teilmenge der Eingabedaten zu antworten. Das kompetitive Lernen wird in einer „kompetitiven Schicht“ implementiert, in der eine Reihe von Neuronen bis auf einige zufällig verteilte Gewichte alle gleich sind.
Der Gewichtsvektor jedes Neurons wird mit dem Eingabevektor verglichen und das Neuron mit der höchsten Ähnlichkeit, das 'Winner Take All'-Neuron, wird aktiviert (Ausgabe = 1). Die anderen sind 'deaktiviert' (Ausgang = 0). Diese unbeaufsichtigte Technik ist ein Kernbestandteil von selbstorganisierende Karten und Feature-Erkennung.
Ein weiteres interessantes Beispiel für zusammengesetztes Lernen ist in Suche nach neuronaler Architektur. Vereinfacht gesagt lernt ein neuronales Netzwerk (normalerweise rekurrent) in einer Reinforcement-Learning-Umgebung, das beste neuronale Netzwerk für einen Datensatz zu generieren – der Algorithmus findet die beste Architektur für Sie! Sie können mehr über die Theorie lesen Hier und Implementierung in Python Hier.
Ensemble-Methoden sind auch ein Grundpfeiler des zusammengesetzten Lernens. Deep-Ensemble-Methoden haben sich als sehr Wirksam, und das Stapeln von Modellen durchgängig, wie Encoder und Decoder, hat an Popularität gewonnen.
Ein Großteil des zusammengesetzten Lernens besteht darin, einzigartige Wege zu finden, um Verbindungen zwischen verschiedenen Modellen herzustellen. Es basiert auf der Idee, dass
Ein einzelnes Modell, sogar ein sehr großes, schneidet schlechter ab als mehrere kleine Modelle/Komponenten, von denen jedes delegiert wird, sich auf einen Teil der Aufgabe zu spezialisieren.
Betrachten Sie zum Beispiel die Aufgabe, einen Chatbot für ein Restaurant zu erstellen.

Wir können es in drei separate Teile unterteilen: Höflichkeiten/Geplauder, Informationsabruf und eine Aktion, und wir entwerfen ein Modell, um uns auf jeden zu spezialisieren. Alternativ können wir ein einzelnes Modell delegieren, um alle drei Aufgaben auszuführen.
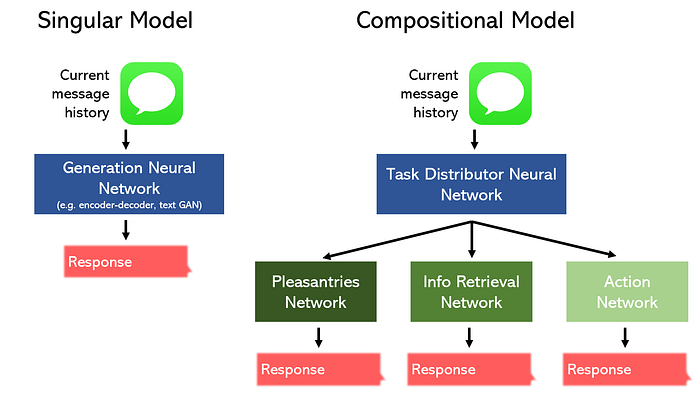
Es sollte nicht überraschen, dass das Kompositionsmodell eine bessere Leistung erbringen kann, während es weniger Platz beansprucht. Darüber hinaus können diese Art von nichtlinearen Topologien mit Tools wie Die funktionale API von Keras.
Um eine zunehmende Vielfalt an Datentypen wie Videos und dreidimensionalen Daten zu verarbeiten, müssen Forscher kreative Kompositionsmodelle erstellen
Lesen Sie mehr über kompositorisches Lernen und die Zukunft Hier.
Reduziertes Lernen
Die Größe der Modelle, insbesondere im NLP – dem Epizentrum der Aufregung in der Deep-Learning-Forschung – wächst, bei viel. Das neueste GPT-3-Modell hat 175 Milliarde Parameter. Vergleich mit BERT ist, als würde man Jupiter mit einer Mücke vergleichen (nun, nicht wörtlich). Ist die Zukunft des Deep Learning größer?
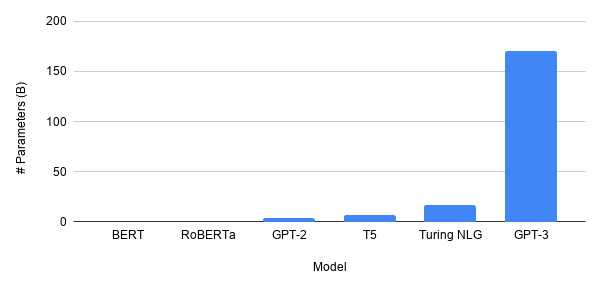
Sehr wohl, nein. GPT-3 ist zugegebenermaßen sehr mächtig, aber es hat in der Vergangenheit immer wieder gezeigt, dass „erfolgreiche Wissenschaften“ diejenigen sind, die den größten Einfluss auf die Menschheit haben. Wenn die Wissenschaft zu weit von der Realität abweicht, gerät sie meist in Vergessenheit. Dies war der Fall, als neuronale Netze Ende des 20. Jahrhunderts für kurze Zeit vergessen wurden, weil so wenig Daten verfügbar waren, dass die Idee, so genial sie auch war, nutzlos war.
GPT-3 ist ein weiteres Sprachmodell und kann überzeugende Texte schreiben. Wo sind seine Anwendungen? Ja, es könnte zum Beispiel Antworten auf eine Anfrage generieren. Es gibt jedoch effizientere Möglichkeiten, dies zu tun (z. B. einen Wissensgraphen zu durchlaufen und ein kleineres Modell wie BERT zu verwenden, um eine Antwort auszugeben).
Es scheint einfach nicht der Fall zu sein, dass die enorme Größe von GPT-3, ganz zu schweigen von einem größeren Modell, machbar oder notwendig ist, da a Austrocknen der Rechenleistung.
"Moore's Law geht irgendwie die Puste aus."
- Satya Nadella, CEO von Microsoft
Stattdessen bewegen wir uns in Richtung einer KI-eingebetteten Welt, in der ein intelligenter Kühlschrank automatisch Lebensmittel bestellen kann und Drohnen selbstständig durch ganze Städte navigieren können. Leistungsstarke Methoden des maschinellen Lernens sollen auf PCs, Mobiltelefone und kleine Chips heruntergeladen werden können.
Dies erfordert eine leichtgewichtige KI: neuronale Netze kleiner machen und gleichzeitig die Leistung beibehalten.
Es stellt sich heraus, dass fast alles in der Deep-Learning-Forschung direkt oder indirekt mit der Reduzierung der notwendigen Parametermenge zu tun hat, was mit der Verbesserung der Generalisierung und damit der Leistung einhergeht. Beispielsweise hat die Einführung von Faltungsschichten die Anzahl der Parameter, die neuronale Netze zur Bildverarbeitung benötigen, drastisch reduziert. Wiederkehrende Schichten beinhalten die Idee der Zeit bei gleichen Gewichten, wodurch neuronale Netze Sequenzen besser und mit weniger Parametern verarbeiten können.
Das Einbetten von Layern ordnet Entitäten explizit numerischen Werten mit physikalischen Bedeutungen zu, sodass die Belastung nicht auf zusätzliche Parameter gelegt wird. In einer Interpretation, Ausfallen Ebenen blockieren explizit Parameter daran, bestimmte Teile einer Eingabe zu bearbeiten. L1/L2-Regularisierung stellt sicher, dass ein Netzwerk alle seine Parameter nutzt, indem sichergestellt wird, dass keiner von ihnen zu groß wird und dass jeder seinen Informationswert maximiert.
Durch die Schaffung spezialisierter Schichten benötigen Netzwerke immer weniger Parameter für komplexere und größere Daten. Andere neuere Verfahren versuchen explizit, das Netzwerk zu komprimieren.
Beschneidung neuronaler Netzwerke versucht Synapsen und Neuronen zu entfernen, die der Ausgabe eines Netzwerks keinen Wert verleihen. Durch das Beschneiden können Netzwerke ihre Leistung aufrechterhalten, während sie fast alles von sich selbst entfernen.
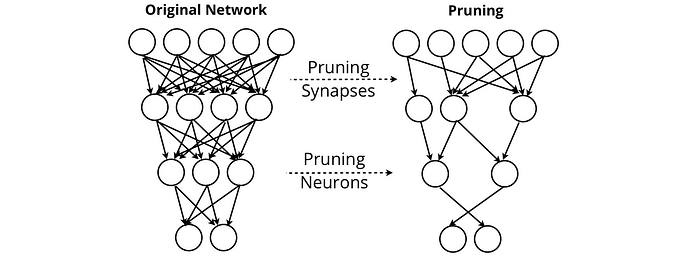
Andere Methoden wie Patientenwissen Destillation Finden Sie Methoden, um große Sprachmodelle in Formulare zu komprimieren, die beispielsweise auf die Telefone von Benutzern heruntergeladen werden können. Dies war eine notwendige Überlegung für die Google Neural Machine Translation (GNMT)-System, das Google Translate antreibt, das einen leistungsstarken Übersetzungsdienst erstellen musste, auf den offline zugegriffen werden konnte.
Im Wesentlichen dreht sich bei reduziertem Lernen um einsatzorientiertes Design. Aus diesem Grund stammen die meisten Forschungen zu reduziertem Lernen aus der Forschungsabteilung von Unternehmen. Ein Aspekt des einsatzorientierten Designs besteht darin, Leistungsmetriken in Datensätzen nicht blindlings zu folgen, sondern sich bei der Bereitstellung eines Modells auf potenzielle Probleme zu konzentrieren.
Zum Beispiel bereits erwähnt Gegnerische Eingaben sind bösartige Eingaben, mit denen ein Netzwerk ausgetrickst werden soll. Sprühfarbe oder Aufkleber auf Schildern können selbstfahrende Autos dazu verleiten, weit über die zulässige Höchstgeschwindigkeit hinaus zu beschleunigen. Ein Teil des verantwortungsvollen reduzierten Lernens besteht nicht nur darin, Modelle leicht genug für die Verwendung zu machen, sondern auch sicherzustellen, dass sie Eckfälle berücksichtigen können, die nicht in Datensätzen dargestellt sind.
Reduziertes Lernen wird in der Forschung im Bereich Deep Learning vielleicht am wenigsten beachtet, denn „wir haben es geschafft, eine gute Leistung mit einer machbaren Architekturgröße zu erzielen“ ist bei weitem nicht so sexy wie „Wir erzielen eine Leistung nach dem neuesten Stand der Technik mit einer Architektur bestehend aus“ von Kajillionen von Parametern“.
Wenn das gehypte Streben nach einem höheren Prozentsatz verstummt, wird, wie die Innovationsgeschichte gezeigt hat, reduziertes Lernen – das eigentlich nur praktisches Lernen ist – unweigerlich mehr Aufmerksamkeit erhalten, die es verdient.
Zusammenfassung
Hybrides Lernen versucht, die Grenzen von überwachtem und unüberwachtem Lernen zu überschreiten. Methoden wie semi-überwachtes und selbstüberwachtes Lernen sind in der Lage, wertvolle Erkenntnisse aus nicht gekennzeichneten Daten zu extrahieren, etwas unglaublich Wertvolles, da die Menge an unüberwachten Daten exponentiell wächst.
Wenn Aufgaben komplexer werden, zerlegt zusammengesetztes Lernen eine Aufgabe in mehrere einfachere Komponenten. Wenn diese Komponenten zusammenarbeiten – oder gegeneinander – ist das Ergebnis ein leistungsfähigeres Modell.
Reduziertes Lernen hat nicht viel Aufmerksamkeit erhalten, da Deep Learning eine Hype-Phase durchläuft, aber schon bald werden praktische Anwendbarkeit und ein einsatzorientiertes Design entstehen.
Danke fürs Lesen!
Erklärung: nur für den akademischen Austausch. Das Copyright dieses Artikels liegt beim ursprünglichen Autor. Wenn etwas nicht stimmt, wenden Sie sich zum Löschen bitte an.